March 3, 2026
From Pixels to Physics: Why VLAs Are the Critical Bridge to Physical AI
Type
Deep Dives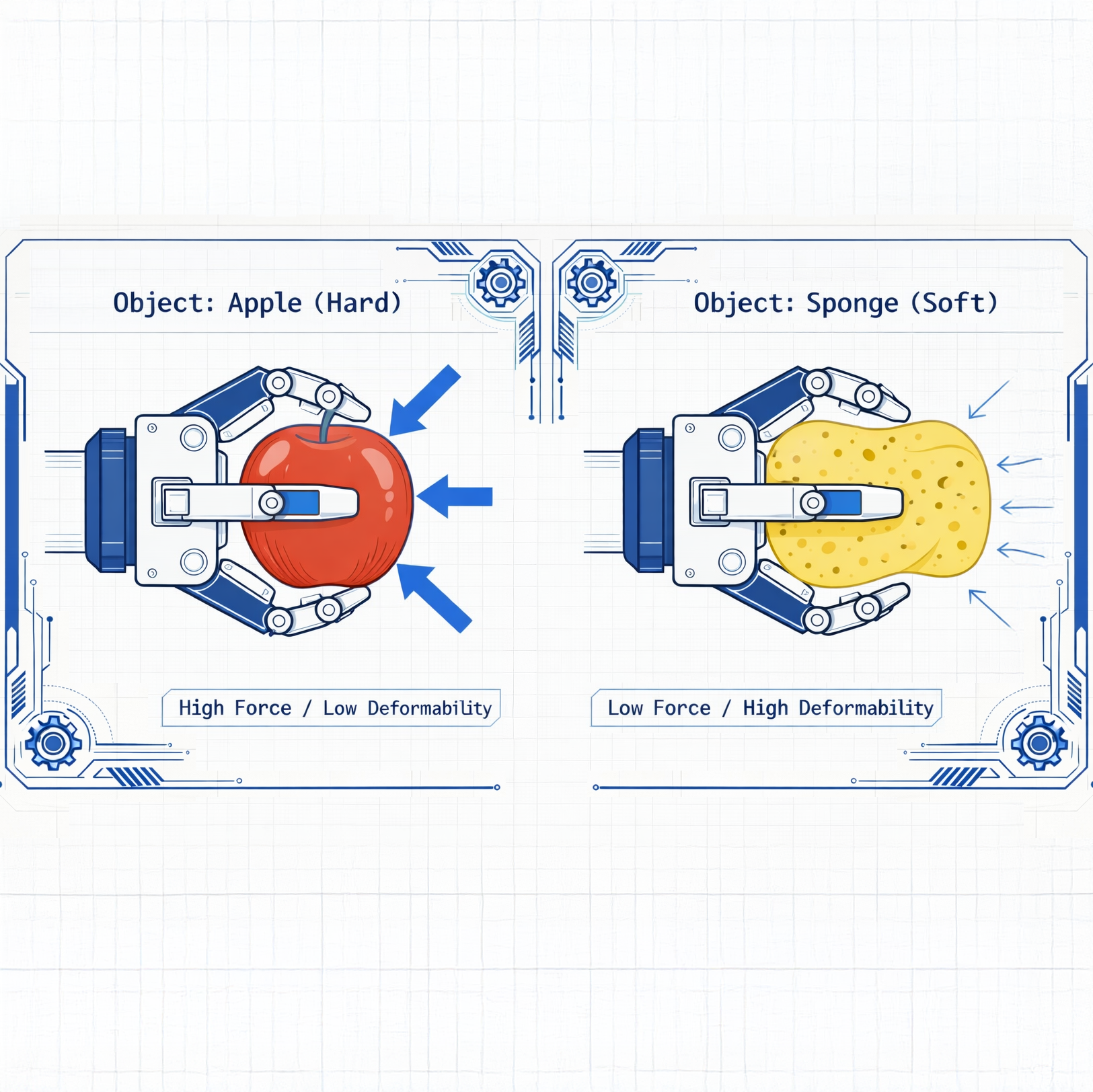
The last few years of Vision-Language Models (VLMs) have been genuinely impressive. The semantic horsepower is real. They’ve unified pixels and prose through shared embedding spaces, visual reasoning, and few-shot generalization with remarkable success.
But perception and manipulation are different challenges.
VLMs can parse scenes, follow instructions, and talk about intent with the confidence of a real mechanic. Then you put them in front of an actual wrench, and their capabilities stall.
A model that can describe how to pick up a wrench has zero operational knowledge regarding the grip pressure required to hold it, the wrist rotation needed, or the corrective micro-adjustments demanded when friction fails.
Because these are not things you learn from images and text. They are things you learn by doing.
This is the wall VLMs run into. They generate tokens. Physical AI executes in torques.
The Third Modality
Vision-Language-Action (VLA) models explicitly bridge this gap between high-level semantic understanding and motor behavior.
Moving beyond text generation, a VLA produces motor commands — the specific, time-sequenced signals that tell a robot’s joints where to move, how fast, and with how much force.
What sounds like a small addition is actually a fundamental shift in what the model is learning to do.
While a VLM maps the world, a VLA learns to actively intervene, accounting for physical dynamics such as resistance, slippage, and material deformation. Language and vision provide the context; action grounding provides the physical competence.
Google DeepMind’s RT-1 made the template tangible: an end-to-end transformer trained on robot interaction data that takes camera input and language instructions, then outputs 7-DOF arm actions.
The model learns that ‘pick up the apple’ requires different motor primitives than ‘pick up the cloth’—not through symbolic reasoning, but by learning distinct visuomotor policies grounded in contact, friction, and failure.
Why Generalization Is the Hard Part
Building a VLA for a single setting is a meaningful engineering milestone, while achieving reliable cross-environment functionality is the critical threshold separating research demonstrations from industrial platforms.
Generalization must occur at multiple levels simultaneously.
At the physical level, a model needs to handle objects it has never seen before, in positions it was never trained in. At the semantic level, it must comprehend task-specific requirements such as routing dishes to the sink, selecting a sponge for a spill, or placing clothes in a laundry basket.
True autonomy requires mastering both levels simultaneously, necessitating training on large, diverse datasets that blend real robot demonstrations with web-scale vision and language data.
We can categorize VLA generalization into three distinct vectors:
- Perception Generalization: Recognizing new objects and scenes.
- Skill Generalization: Executing the same intent under new geometries, materials, and contact conditions.
- Embodiment Generalization: Transferring capability across different robot arms, grippers, and sensor layouts.
OpenVLA, trained on nearly a million robot manipulation trajectories drawn from many different platforms and environments, demonstrated that a single generalist model could transfer meaningfully across embodiments—adapting to new hardware with relatively modest fine-tuning. Perception generalizes broadly; motor control requires targeted adaptation.
Physical Intelligence’s π0.5 pushed this further, deploying robots in homes that were entirely absent from the training data and asking them to complete extended cleaning tasks. The model would make mistakes, recover, and try again — not because it had seen that specific home before, but because training on sufficiently diverse environments had built something closer to genuine flexibility.
This out-of-distribution performance is the definitive benchmark for this model class.
How VLAs Get Built
As discussed above, most successful VLA recipes follow a pragmatic arc: integrating a strong pretrained vision-language backbone, adding an action interface, and training the full system on robot episodes via imitation learning and behavior cloning.
The backbone contributes broad visual and semantic priors. The robot data contributes grounded control.
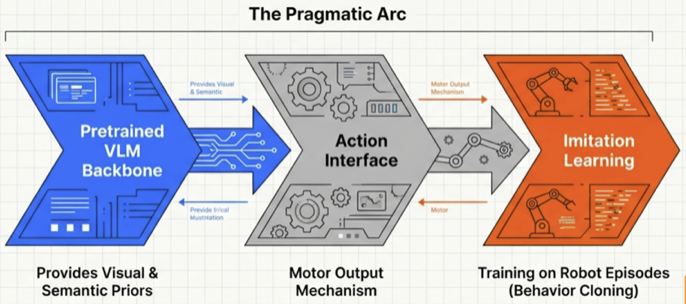
Data quality supersedes abstract volume. Teleoperated demonstrations capture intent-to-action mappings. Kinesthetic teaching captures contact behavior that humans manage subconsciously. Rollouts paired with correction teach recovery, transforming fragile prototypes into robust, production-ready platforms.
Web-scale data enhances perception and language grounding, while precise contact competence requires direct embodied interaction.
The Reasoning Frontier
The next evolution in VLAs integrates explicit reasoning alongside perception and action.
Moving beyond direct visual-to-motor mapping, reasoning VLAs decompose tasks into intermediate steps, effectively calculating logic and intent prior to physical execution.
This drives significant practical value: a robot approaching an ambiguous situation can articulate its interpretation before committing to an action, making the system highly reliable and easier to audit.
In the event of a failure, there is a clear reasoning trace to inspect. NVIDIA has framed this as a core property of next-generation physical AI systems, where interpretability and adaptability scale together.
The Bridge That Matters
The gap between today’s LLM deployments and real physical AI is fundamentally architectural. Scaling context windows or benchmarks is insufficient. Closing this divide requires transitioning from a system that processes and describes the world to one that has learned to change it.
VLAs are that definitive architectural step. They carry the semantic understanding built into foundation models and extend it into the physical domain, equipping robots with the ability to interpret instructions, read environments, and act with reliable competence across novel conditions.
This is what makes them the bridge. They represent a critical, necessary evolution toward AI that operates in the physical world.
Share Story


