May 12, 2026
AI Infrastructure Has a Utilization Problem
Type
Deep DivesContributor
Murat Kilicoglu
AI Infrastructure Has a Utilization Problem
By Murat Kilicoglu, Partner at Cota Capital
For a while, the entire AI infrastructure market could be explained with one sentence: if you could get GPUs, you were in business.
That was true. It was also temporary. When GPUs were hard to get, access itself carried a lot of value. That phase is fading. Hardware is still expensive. It is still hard to get in the exact quantity and configuration many customers want. But the harder question now is how much useful work a company can get out of the hardware once it has it.
It becomes obvious when you talk to the businesses that run these systems. A cluster can look fine on paper and still run poorly. GPUs sit reserved for jobs that never launch. Capacity gets stranded because one workload needs more memory, another needs more bandwidth, and the system cannot place either one cleanly. Teams spend heavily on high-end hardware and then realize the problem is latency, memory pressure, networking, scheduling, orchestration, and the demand that rarely arrives in the neat shape the architecture assumed.
This is also where scale-up and scale-out become important. In AI infrastructure, scale-up usually means making a single system, rack, or tightly coupled domain more powerful: more accelerators, more local memory, faster interconnect, and less distance between the parts of the system that need to communicate constantly. That is useful when the workload has a hot path that cannot tolerate much delay. Scale-out is different. It means spreading work across more machines, racks, or sites. That gives an operator more aggregate capacity, but it also introduces new problems: network congestion, placement, synchronization, state management, and more ways for the system to waste time waiting on itself.
Both approaches are crucial. Scale-up gets expensive quickly and runs into physical limits around power, thermals, packaging, and hardware availability. Scale-out gives you reach, but only if the network, scheduler, and serving layer can keep up. A lot of AI infrastructure companies are learning this the hard way. The unit of competition is becoming the system around the GPU.
A useful way we think about this market is that AI infrastructure sits between the model and the physical layers. The model layer is where people tend to typically focus attention, which has foundation models, fine-tuned models, inference APIs, etc. The physical layer is the base of the system, with data center footprint, cabinets, servers, power, cooling, cabling, and the physical network. AI infrastructure layer in between is where a lot of the economic value gets won or lost. This middle layer decides whether a cluster behaves like productive infrastructure or an expensive pile of parts. The system needs to move data quickly, place workloads intelligently, preserve latency under load, isolate tenants, recover from failures, and give operators a clear view of what is actually being used.
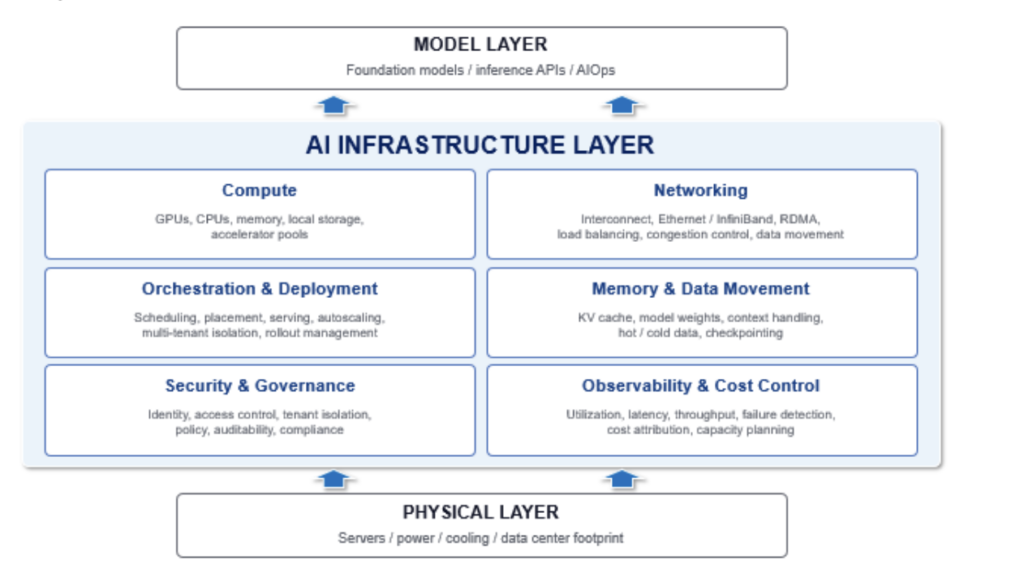
This is the part of the AI market we find intriguing now. The interesting companies are the ones helping customers get better utilization from the hardware they already own. It is a less flashy problem, but it is the one operators and customers actually feel.
The hard problems are latency, memory, and coordination
People often talk about GPUs as if they were a single resource you need to run AI. That is not how these systems behave in production. A GPU is compute, but it is also memory, bandwidth, locality, queue depth, and a set of constraints around what can run next to what.
This shows up most clearly in inference. Training gets the headlines, but inference gets the operational burden. Requests arrive unevenly. Prompt lengths vary. Some customers care most about latency. Others care most about cost. Many want both.
Memory is often the first constraint. A model has to be loaded. State has to be maintained while requests are served. Longer prompts and longer outputs consume more room. KV cache, which stores a model’s previously computed Key and Value attention tensors so it can generate the next token much faster, becomes a real operating concern. If memory is handled poorly, latency rises, throughput falls, and companies start buying hardware to compensate for a software problem.
But memory is only part of it. A serving layer can lose efficiency because the scheduler makes suboptimal placement decisions. Autoscaling can lag demand. One queue can fill while another sits idle. A workload may have available GPUs but not the right topology. A node may look usable in an inventory system but be a bad fit because of network distance, memory pressure, tenant policy, or deployment state. If the network is the constraint, scale-out adds coordination cost. If latency is the promise to the customer, utilization cannot be improved by simply packing every machine as tightly as possible.
Sharing expensive hardware
Many workloads do not need an entire top-tier GPU all the time, and many enterprise workloads are too uneven to justify dedicating whole devices to one job at a time.
If expensive hardware can be divided, shared, and reassigned intelligently, the economics improve. A provider can serve a broader mix of workloads without just buying more machines. A customer can get reliable performance without paying for unused capacity. Most real environments need that flexibility. They are not running one perfect benchmark job over and over. They are juggling internal copilots, evaluation runs, customer-facing inference, fine-tuning, experiments from different teams, and whatever new workload arrived that week. Some jobs are urgent. Some are cheap. Some are noisy. Some do not belong on premium hardware at all.
If the platform cannot separate those workloads cleanly, companies try to solve the problem the expensive way by buying more, reserving more, leaving slack everywhere, and hoping nobody asks why the bill keeps rising.
Where the interesting AI infra businesses get built
What I like about this part of the market is that it cuts through a lot of noise. Infrastructure buyers do not care much about grand theories. They care whether the system works, whether performance holds up when usage gets choppy, and whether the bill makes sense at the end of the month. If you can improve those three things, people keep paying you.
That is why some of the better AI infrastructure companies will be built around making expensive systems easier to run. They will not all look the same. Some will focus on scheduling and placement. Some will focus on memory and serving efficiency. Some will focus on networking, especially as more customers move from single-cluster thinking to scale-out deployments. Some will focus on inference across mixed compute environments, where not every workload belongs in the same cloud region or on the same class of accelerator.
You can already see strong companies emerging across this stack: Cast AI is increasingly solving customers’ problems on GPU/memory/CPU utilization; Upscale AI is working on networking for heterogeneous scale-out clusters; and OpenInfer is aimed at coordinated inference across distributed CPUs, GPUs, NPUs, and edge devices. We believe this is not one monolithic AI infrastructure market, but a set of painful constraints that show up once customers try to run AI systems at scale either in data centers or through gateways or at the edge.
We like these businesses better than those built only around scarcity. Scarcity can make a company look better than it is. If supply loosens, and in cyclical markets it usually does, that advantage fades quickly. A company that improves utilization remains useful in both environments. When hardware is scarce, better utilization stretches what is available. When hardware is easier to buy, better utilization keeps spending under control.
There is also a healthy kind of discipline in this category. Resource management forces honesty. Either the cluster runs better or it does not. Either customers get more work from the same machines or they do not. I suspect that, over the next few years, the conversation around AI infrastructure will become more grounded. We’ll still likely see news like a hyperscaler or a neocloud reaching millions of GPUs in a single data center, but we’ll also see more discussion of what it takes to run a tighter cluster, with more attention on utilization, stability, and cost efficiency.
Share Story


